AI-Ready Data: A Technical Assessment. The Fuel and the Friction.
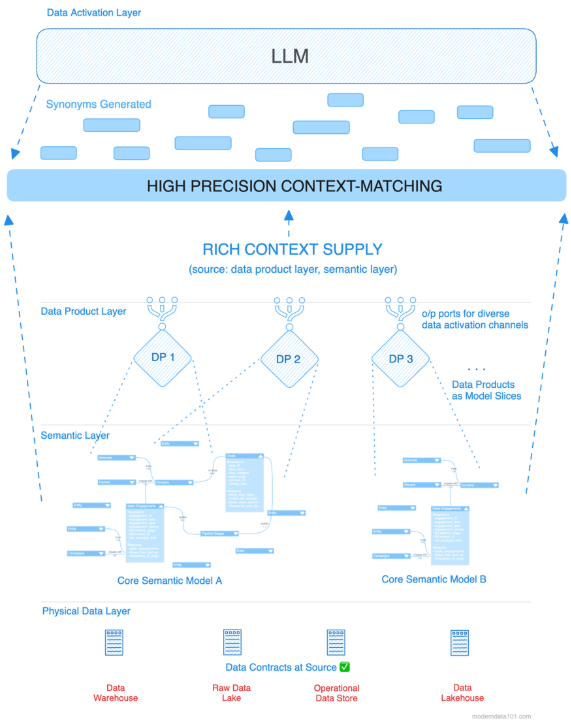
Enterprises everywhere are pouring resources into AI to unlock efficiency and innovation, and outpace competition. Yet beneath the surface, data pipelines are convoluted in a hidden architecture of constraints, blocking AI from realistically scaling.Key Findings:67% of AI projects fail due to data readiness issues¹14% of organizations possess the data maturity necessary to exploit AI's potential²6-8 months per AI use case with traditional approaches versus 2-3 months with modern architectures60-70% Data quality in legacy systems versus 99%+ required for production AI applicationsThis paper highlights four technical barriers to practical or scalable AI solutions: semantic ambiguity, data quality degradation, temporal misalignment, and format inconsistency. These issues require inline governance solutions and data architectures specifically designed for machines instead of human users.Organizations must transition from traditional ETL-based data pipelines to AI-native data product architectures that ensure quality, provide semantic clarity, and deliver the reliability necessary for production AI systems.