Knowledge Graphen und Large Language Models: die perfekte Kombination!
Artikel
Knowledge Graphen und Large Language Models: die perfekte Kombination!
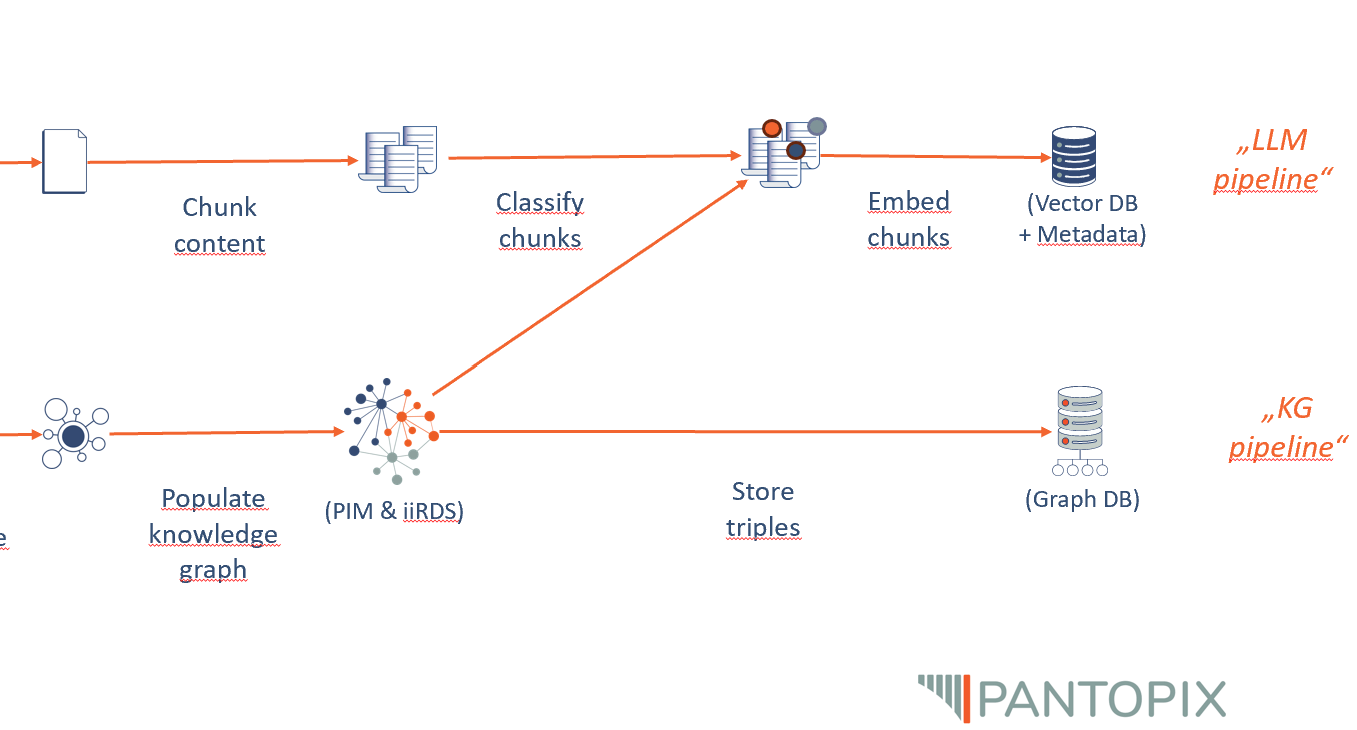
Out-of-the-Box-Lösungen für RAG-Systeme (Retrieval Augmented Generation) verbreiten sich immer weiter. Sie versprechen, das Wissen eines Unternehmens aus Dokumenten wie PDFs oder Word-Dateien mithilfe von Large Language Models (LLMs) in Form eines Chats zugänglich zu machen. In diesem Kontext stellt sich unweigerlich die Frage: Welche Rolle spielen Knowledge Graphen in diesem Szenario noch – und welchen Mehrwert können sie bieten? Anders formuliert: Wenn ich alle meine Texte per Chat verfügbar machen kann, warum sollte ich Geld- und Zeitressourcen in die Strukturierung meines Wissens investieren? Aus Sicht eines Unternehmens, das diese Ressourcen bereits investiert, also einen Knowledge Graphen zur Verfügung hat, stellt sich wiederum die Frage, ob ein LLM noch Mehrwert bieten kann. Dies gilt insbesondere da LLMs ja für ihr Halluzinieren und Falschinformationen bekannt sind. Strukturierte Daten für das Large Language Model (LLM) Um Textdateien wie PDFs für einen LLM-getriebenen Chat verfügbar zu machen, müssen die Textdateien in Sinnabschnitte zerlegt (Chunking) und jeder Textteil in Vektoren überführt (Embeddings) und abgespeichert werden (Vektordatenbank).